Analysing 5 years of Amazon Kindle reading (and how you can too!)
One of my favourite possessions that I use almost every day is my Kindle Paperwhite 3 from 2016. I purchased the Paperwhite 5 recently (comparison coming soon!), and decided to analyse the hundreds of books read on my previous Kindle before I say goodbye to it!
In this post I’ll talk through a spreadsheet I created to analyse my own Kindle data, and provide details on how you can easily analyse your own. If you’d just like to see the outcome of the analysis, here’s the Kindle spreadsheet!
Preparing the spreadsheet
Exporting your Kindle data from Amazon
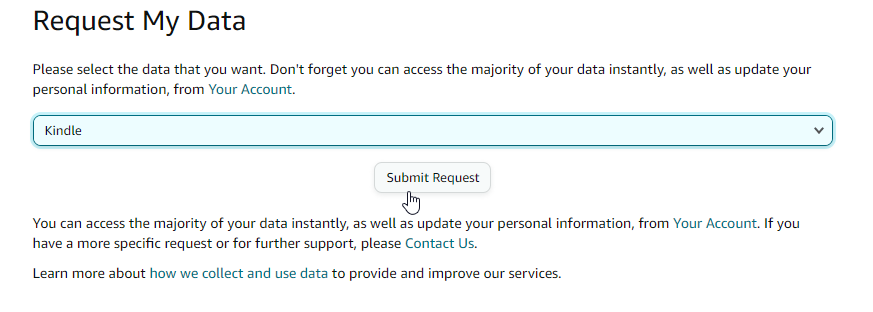
First, you need to export your purchase history from Amazon. The URL for this varies by country, e.g. Amazon US and Amazon UK, if you’re elsewhere just change the domain to your usual Amazon domain.
You’ll then need to select the “Kindle” category, and click Submit Request. It may take a few days to actually receive the download links via email if you use your Kindle a lot, but it’ll arrive eventually!
Preparing your data
When the email eventually arrives, it’ll contain a link to download a lot of Kindle-related data. For me it had over 50(!) individual pieces of downloadable data, the two we need to download are Kindle.KindleDocs.zip and Kindle.Devices.ReadingSession.zip.
Unzip both of these downloaded items (how to unzip), and then make sure you have:
- Inside
Kindle.KindleDocs/datasets/Kindle.KindleDocs.DocumentMetadata, a file calledKindle.KindleDocs.DocumentMetadata.csvcontaining all books on your Kindle. - Inside
Kindle.Devices.ReadingSession, a file calledKindle.Devices.ReadingSession.csvcontaining all your Kindle reading sessions.
If they’re both there, then you’ve got all you need!
Creating the spreadsheet
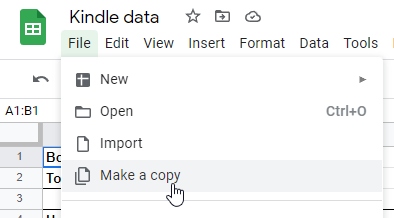
Head over to my Kindle analysis spreadsheet, and click File -> Make a copy, then save it as whatever you want in your Google Drive:
Importing your data
By default, you’ll end up on the “Calculations” spreadsheet. These numbers obviously won’t match your data yet, we need to import it!
Books
First, we need to import a list of all books in your library:
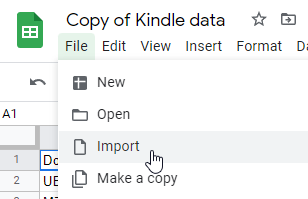
- Navigate to the
Kindle.KindleDocs.DocumentMetadatasheet, click so cellA1is selected, then clickFile->Import data. - Select your
Kindle.KindleDocs.DocumentData.csvfile you prepared earlier. - When importing, make sure you select “Replace data at selected cell”! Otherwise, you’ll lose some of the book-specific calculations in the spreadsheet.
- You should have a complete list of all books on your Kindle, along with some equations (columns
L-O) for later,
| Step 1 | Step 2 | Step 3 | Step 4 |
|---|---|---|---|
 |
 |
 |
 |
Reading sessions
Now, we need to import all of your Kindle reading sessions:
- Go to the
Kindle.Devices.ReadingSessionspreadsheet. - Perform the same steps as before, selecting your
Kindle.Devices.ReadingSession.csvfile instead. - You should have a very, very long list of all your reading sessions:
All done! Going back to the first sheet should now show lots of lovely data analysis!
Viewing the spreadsheet
One more time, the Kindle spreadsheet full of my data which you can copy is here.
Per book information
First, on the ...DocumentMetadata tab, you can see a summary of the reading data grouped by book. The data itself is pretty messy, so only simple calculations are done here. For each book you can see the number of reading “sessions”, when the book was first opened, how many milliseconds the sessions lasted for, and the total number of page turn events.
Using “The Wind in the Willows” as an example, according to the data I read 507 pages, across 82 reading sessions, for a total of 5.5 hours. The book itself is only 200 pages, so whilst the time might be correct (factoring in time with the screen on but not reading), the number of sessions and page turns are probably incorrect:
| Title | Sessions | Started | Total milliseconds | Pages turned |
|---|---|---|---|---|
| The Wind in the Willows | 82 | 2021-12-18T08:47:52Z | 19898800 (5.5hrs) | 507 |
Overall data
Heading over to the main Calculations sheet, we can see some overall totals:
- Books with valid reading data: 242
- Total reading hours: 1,430.79
This works out to about 50 kindle books and 280 hours of reading between 2017-2022, which sounds about right based on my Goodreads book history.
Reading by time and year
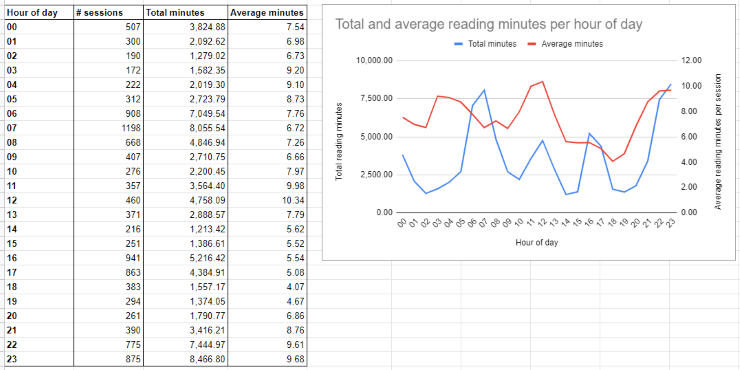
Time of day
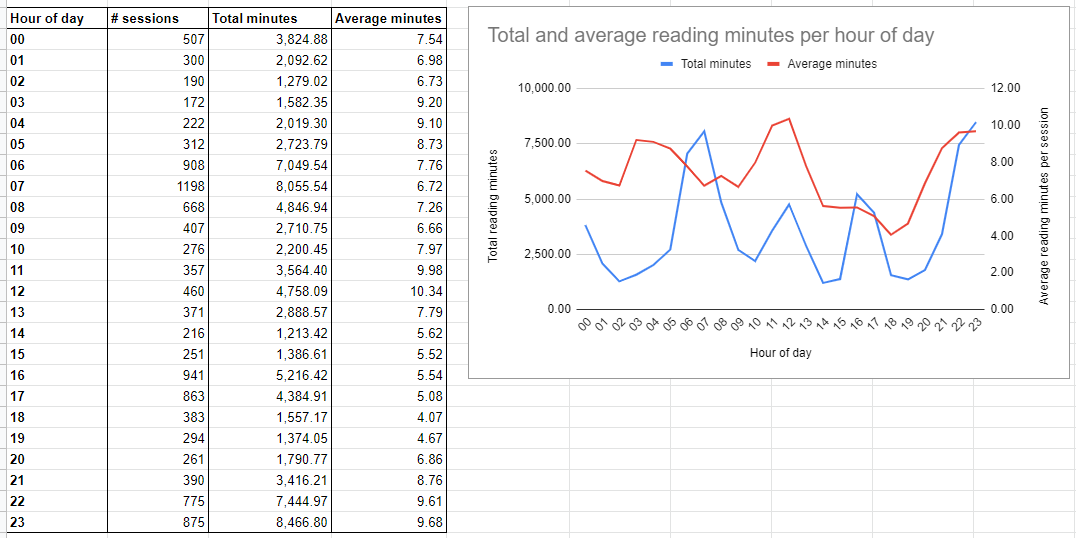
The blue line on the graph shows when I read most, and I’m not at all surprised to see my morning commute, lunchtime, evening commute, and before sleeping as spikes on there!
I’m not sure how reliable the red line’s values are, since it indicates an average reading session of under 10 minutes which just isn’t true. I’d also expect reading sessions in my morning and evening commutes to be of similar average duration. The spikes for lunchtime (1 hr) and before sleeping (~1hr) are probably correct.
Year
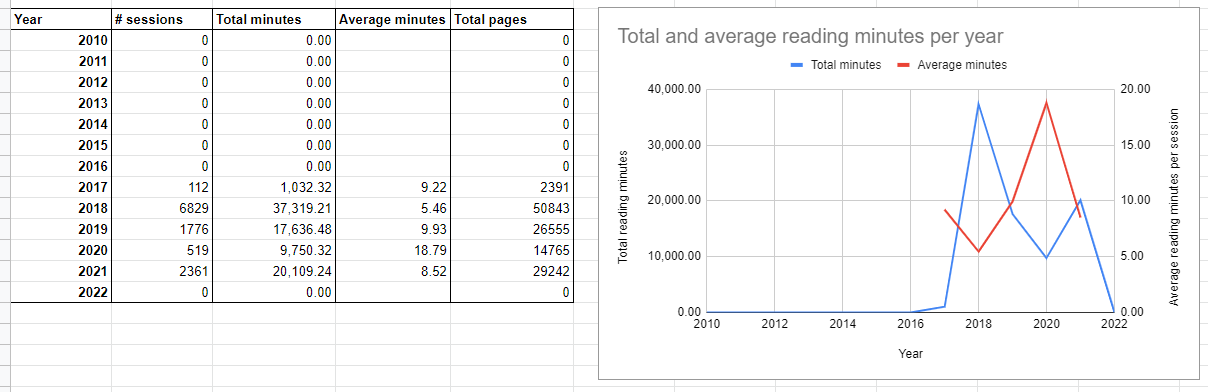
I only have Kindle data since I bought mine in 2016 (obviously!), and it shows interesting trends that weren’t exposed in my Goodreads analysis.
The red line (average minutes per session) shows I’ve had longer but fewer reading sessions whilst working remotely. The blue line indicates I previously used my Kindle much more when I was commuting, now I tend to read physical books more since I’m at home. This also explains why my morning and evening commutes show up so clearly in the previous time of day graph.
Books read for longest and shortest time
| Read time rank | Book title |
|---|---|
| 1 | The Rig |
| 2 | One minute to midnight |
| 3 | Children of Ruin |
| 4 | Consider Phlebas [The Culture 01] |
| 5 | Cities in Flight |
| 238 | Gravity’s Rainbow |
| 239 | Team Topologies: Organizing Business and Technology Teams for Fast Flow |
| 240 | The First 90 Days, Updated and Expanded: Proven Strategies for Getting Up to Speed Faster and Smarter |
| 241 | The Religious Experience of Philip K Dick |
| 242 | Short Happy Life of the Brown Oxford and Other Stories, The |
The longest read times are, unsurprisingly, a mixture of longer books and those that require more attention! The Rig and Children of Ruin are both 600+ pages, whilst One Minute to Midnight is only 448 but requires careful reading. Consider Phlebas is interesting as it’s only 450 pages and an easy read, but I didn’t enjoy it (3/5 stars) so got easily distracted whilst reading, hence a long total read time.
For the shortest read times, they’re all books I opened on Kindle, and then decided to not read almost immediately! For some of them, e.g. “The Religious Experience of Philip K Dick” was included in a collection but was a comic, which I’d rather read on a larger screen. Similarly Team Topologies was quite diagram heavy, so I purchased a physical copy instead.
Extra notes
Commentary on data
Overall, it’s hard to get a feel for how reliable any of this data is. There’s an inherent uncertainty in trying to use “Kindle screen on time” as “reading time”, since I often take short breaks whilst reading to check email / messages. Instead, it’s more of a “maximum possible reading time”, and even then the raw data seems to show some overlapping sessions.
Additionally, the data I exported from my Amazon account contained no fewer than three different files full of reading session data. None of these matched up, and all contained slightly different data and sessions, so I went for the one that was easiest to parse and most comprehensive!
The reading sessions also seem to cut off too early. Most of my sessions are around 30 seconds, featuring only 1 page turn. This might be because I read at a relatively high word density (font size 2), so turn the page much less frequently than someone with fewer words per page, throwing off whatever logic Amazon uses to determine a session.
Finally, I’m not sure if my spreadsheet will work for someone using non-Kindle devices (e.g. web / app), or books from the Amazon store. Almost all of my books are sideloaded, and read on a single device, I can only hope the calculations are generic enough to work for others!
Commentary on calculations
This analysis relied heavily on calculations created whilst analysing my Amazon purchases, with 2 techniques I hadn’t used before:
- Using
COUNTIF([cells], ">0")to get a count of the number of books that had at least 1 reading session. This could then be used to get the row number of the bottom 5 books by read time. - Using a somewhat complex formula to order an unsorted spreadsheet by a specific column, pick the row at a specific position, and then fetch the value. This was used to lookup book title by reading time rank:
=INDEX([desired column], MATCH(LARGE([search column], [rank]), [search column], 0))e.g.
=INDEX(Kindle.KindleDocs.DocumentMetadata!B2:B10000, MATCH(LARGE(Kindle.KindleDocs.DocumentMetadata!N2:N10000, A55), Kindle.KindleDocs.DocumentMetadata!N2:N10000, 0))